
Advanced Data Modeling with Firestore by Example
In the previous lesson, we learned the fundamentals of relational data modeling with Firestore. Today I want to push further and look at several more practical examples. In addition to data modeling, we will look at techniques like duplication, aggregation, composite keys, bucketing, and more.
Keep in mind, Firestore is still in beta. Firebase engineers hinted at some really cool features on the roadmap (geo queries, query by array of ids) - I'll be sure to keep you posted :)
Advanced Techniques in NoSQL
There are several fundamental techniques at your disposal for managing complex NoSQL structures. Let’s talk briefly about each one of them.
Duplication
Data duplication is a very common technique to eliminate the need to read multiple documents. Simple example - we might duplicate or embed a username on every tweet doc to avoid making secondary query to the user doc. Or we might duplicate 20 recent tweets on the user document to show on the user profile. This strategy results in faster reads, but slower writes. Think about it - we can read all data in a single document, but may need to update multiple documents when the embedded data changes.
Aggregation
Data aggregation is the process of analyzing a collection of data, then saving the results on some other document. The simplest example would be saving a count of the total documents in a collection. Normally, Firestore aggregation is done server side via Cloud Functions.
Composite Keys
A composite key is simply the combination of two or more unique document ids, for example userXYZ_postABC. This is especially useful for modeling relationships in denormalized structures because it can enforce a unique relationship between the two documents.
Bucketing
Bucketing is a form of duplication/aggregation that breaks collections into single documents. Using Twitter as an example, let’s imagine we have a collection of tweets, but want to bucket a certain user’s tweets month-by-month. This would allow us to read tweets for a given month very efficiently, but the drawback is some additional bookkeeping to ensure all data stays in sync when updates occur on the source document (Twitter probably has good technical reasons for not allowing you to update tweets).
tweets/{tweetId}
tweetData (any)
februaryTweets/{userId}
userId
tweets [
{ tweetData }
]
Sharding
In many NoSQL databases, you must shard to scale. Sharding is just the process of breaking the database down into smaller chunks (horizontal partitioning) to increase performance.
In Firestore, sharding is handled automatically. The the only scenario where you may need to control sharding is when you consistently have many write operations occurring at intervals of less than 1s. Imagine the compute requirements of updating the like count on a new tweet from Selena Gomez.
Pipelining (Unique Firebase Feature)
Another cool feature in the Firebase SDK is the ability to make read requests in a non-blocking manner called pipelining as explained by Frank van Puffelen. When you query Firestore, you don’t need to wait for response A to send request B. You can send all requests individually and Firebase will respond with data as soon as it becomes ready.
Pipelining isn't a data structuring technique, but it drives our decision-making process.
Let’s imagine you have an array of document ids. You can pipeline each request from a child component by looping over the ids, then performing a document read from the child component, i.e afs.doc('items/' + id). Because the requests are non-blocking, there’s no major performance hit for structuring your app this way.
<parent-comp>
<child-comp *ngFor="let id of documentIds">
<!-- afs.doc('items/' + id) -->
</child-comp>
</parent-comp>
Group Collection Query
A group collection query occurs when you want to query a common subcollection across its parent owners. For example, you might to get blog posts for all users who wrote a post categorized as Angular.
It is not possible to make this query via the subcollection. The easy solution is to denormalize posts to a root collection, but if that’s not possible here’s plan B…
First, embed some duplicated data on the parent. When a new post is created in the subcollection, we update the categoriesUsed object on the parent doc where the category is the key.
users
- userData (any)
- categoriesUsed {
angular: true
vuejs: true
}
++ posts/{postID}
-- content
-- category: angular
This opens the door to make a query like so:
users.where('categoriesUsed.angular', '==', true);
At this point we have all the users who posted to Angular, then we can query each user’s posts subcollection individually and join the data client-side.
Shopping Cart + Ecommerce NoSQL Model
Building an ecommerce solution is no simple task - that goes for both SQL and NoSQL. In this example, I show you how to model a shopping cart with basic inventory management. Keep in mind, you are likely to have other concerns, such as payments, returns, etc.
- One-to-One: User to Cart
- Many-to-Many: Products to Users (via Cart)
- One-to-Many: User to Orders
Shopping carts work great with Firebase Anonymous auth when your users can checkout as a guest.
Data Model
The challenges are as follows:
Product prices may change and should be reflected in the cart. Product inventory stock is limited.
products/{productID}
-productInfo (any)
-- amountInStock (number)
users/{userID}
-- userInfo (any)
++ orders
-- items [
{ product: productID, qty: 23 }
]
carts/{userID}
-- total (number)
-products {
productId: quantity
}
]
Users (root collection): Basic user data
Products (root collection): Product data and current inventory.
Carts (root collection): A one-to-one relationship is created by setting the userID === cartID for documents in either collection. When an order placed, the cart data can be cleared out because there is no need for a user to have multiple carts.
Orders (user subcollection): When an order is created and confirmed, you can run a cloud function to decrement the product availability.
User Follow/Unfollow System
Naturally, let’s use Twitter as our example here. We can take advantage of composite keys to manage the relationship in its own collection. Using a unique ID of followerID_followedID is like saying userFoo follows userBar.
Data Model
users/{userID}
-- userInfo (any)
-- followerCount (number)
-- followedCount (number)
relationships/{followerID_followedID}
-- followerId (string)
-- followedId (string)
-- createdAt (timestamp)
Users (root collection): Basic user data with aggregated follow counts.
Relationships (root collection): This works similar to a intermediate table in SQL, with a composite key to enforce uniqueness for each user to user relationship.
Sample Queries
Does UserA follow UserB:
db.collection('relationships').doc(`${followerId}_${followedId}`);
Get a user’s 50 most recent followers:
db.collection('relationships')
.where('followedId', '==', userId)
.orderBy('createdAt', 'desc')
.limit(50);
Get all users that are being followed
db.collection('relationships').where('followerId', '==', userId);
Threaded Comments or Hierarchy Tree Structure
Let’s look at how we might model a tree structure that goes multiple levels deep - think threaded comments on Hacker News or a directory of subcategories. In fact, I am modeling my data after Hacker News which is hosted on Firebase RTDB.
This implementation is designed to take advantage of pipelining in Firebase - instead of requesting a single collection, we will request a bunch of documents individually.
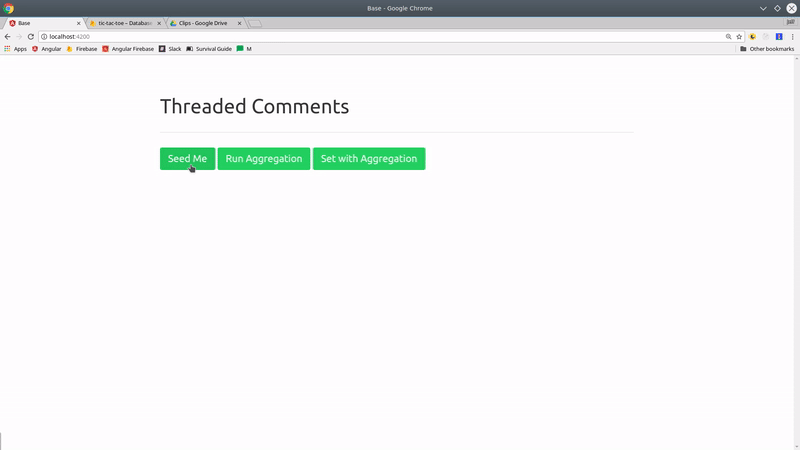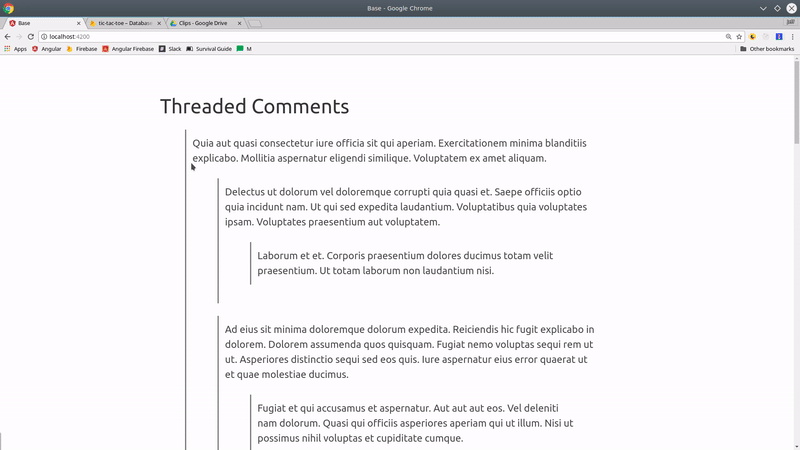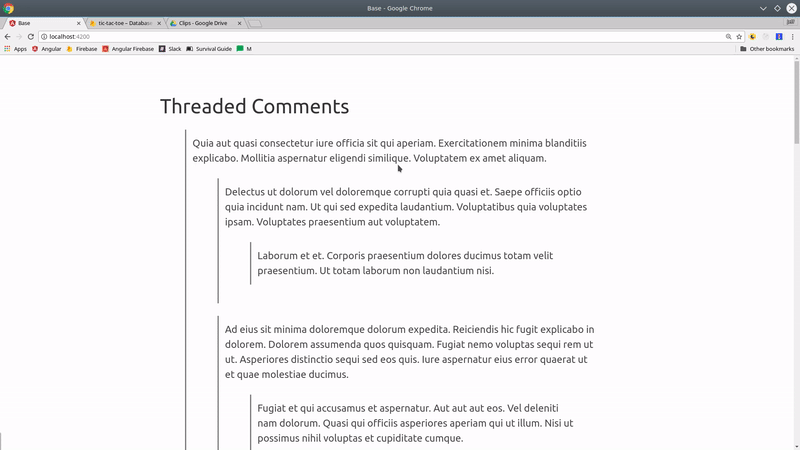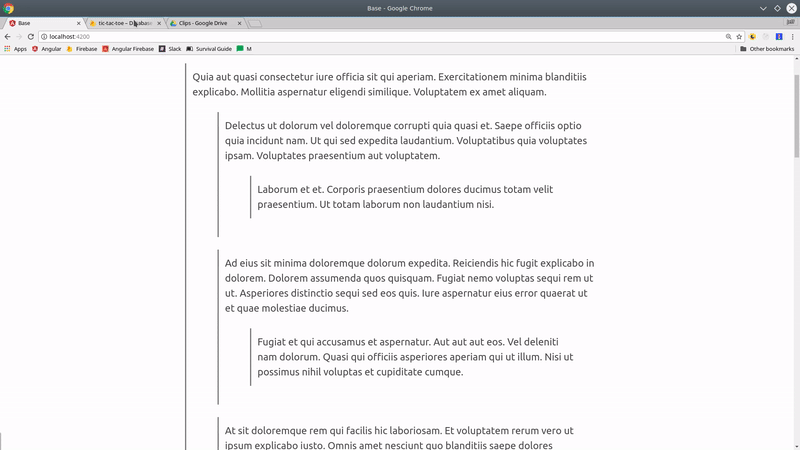
Threaded comments hierarchy structure in Firestore
In the future, Firestore may support a queries based on an array of doc IDs
Data Model
posts/{postId}
++ comments/{commentB}
-- createdAt (date)
parent: commentA
children: [ commentC, commentD ]
Recursive Query Structure in Angular
First start by querying the root comments with comments.where('parent', '==', null), then pass them to our comment component.
<app-comment *ngFor="let comment of comments | async"
[commentId]="comment.id">
</app-comment>
This allows us to build a recursive component (a component that calls itself) to render out a tree. In other words, while the comment document has children, it will continue rendering new branches of the threaded comment tree. It would also be easy to lazy load each branch by adding “view replies” button before loading the children.
@Component({
selector: 'app-comment',
template: `
<div *ngIf="comment | async as c" class="indent">
{{ c.text }}
<div *ngIf="c.children">
<app-comment *ngFor="let kid of c.children"
[commentId]="kid">
</app-comment>
</div>
</div>
`,
styles: []
})
export class CommentComponent implements OnInit {
@Input() commentId;
comment;
constructor(private db: AngularFireStore) {}
ngOnInit() {
this.comment = this.db.doc('comments/' + this.commentId);
}
}
Tags or HashTags
Going back to the Twitter theme, let’s now try to model hashtags in Firestore. Hashtags must be a single continuous string and should be case insensitive. This means we can use the tag itself as the document ID. For example, a hashtag of #AngularFire would have a doc ID of angularfire.
Whenever a new tweet is created, you can use a cloud function to aggregate the postCount property on the tag document.
Data Model
tweets/{tweetId}
-- content (string)
-- tags: {
angular: true,
firebase: true
}
tags/{content}
-- content (string)
-- tweetCount (number)
Sample Queries
Get all tweets with a specific tag:
db.collection('tweets').where('tags.angular', '==', true);
// Or
db.collection('tweets').orderBy('tags.angular');
Get the most popular tags:
db.collection('tags').orderBy('tweetCount', 'desc');
Get a specific tag:
tagId = 'SomeCoolTag'.toLowerCase();
db.doc('tags/' + tagId);
The End
I love data modeling. If you want to talk about your own complex data structure challenges, please reach out on Slack. In the future, I will take some of these models and build out entire features that you can drop into any Angular app.