
BigQuery ML Quickstart
BigQuery is a serverless Data Warehouse that makes it easy to process and query massive amounts of data. It supports standard SQL queries in a web-based UI, via the command line, or with a variety of client libraries. In addition, it recently landed support for integrated machine learning, allowing you to build predictive models without data science skills.
What can you do with Big Query?
- Stream data to business intelligence tools like Data Studio, Tableau, etc.
- Combine Web Analytics with iOS/Android on Firebase.
- Organize and connect multiple data sources.
- Build a horse racing machine learning model 🏇
In the following lesson, we will harness the data-crunching power of 👾 BigQueryML, along with DataStudio and DataLab, to build a predictive model from historical Horse Racing Data. Our goal is to turn this dataset into an ML model.
Import Data into Big Query
The first step is to import your data into BigQuery. Create a new Google Cloud Platform or Firebase project, then navigate to the BigQuery Web UI.
Upload Data to Cloud Storage
Download the Horse Racing Dataset from Kaggle, specifically the horses.csv file. Because this file is larger than 10Mb, we need to first upload it to a GCP storage bucket.
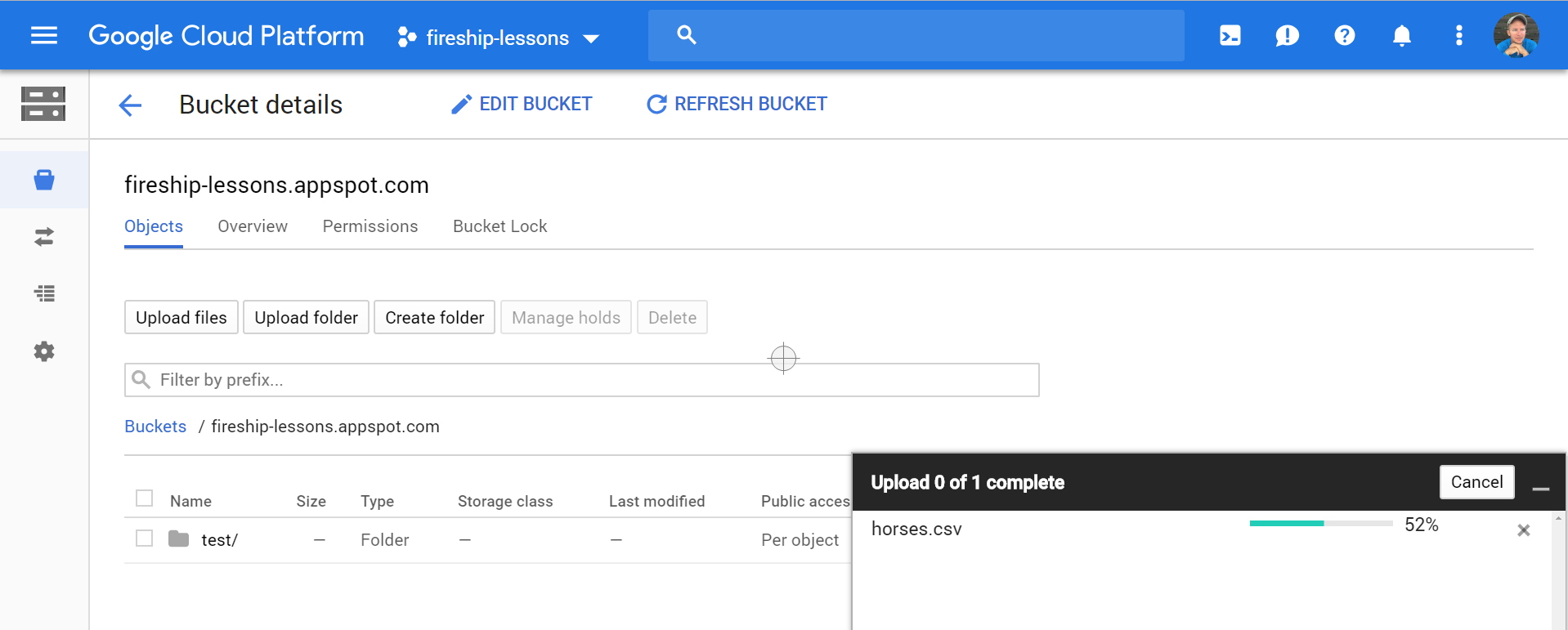
Upload horses.csv to a cloud storage bucket
Create a Dataset & Table
Click on the + Add Data button and make sure your project is pinned, then click on Create Dataset. Provide a name and use the default options.
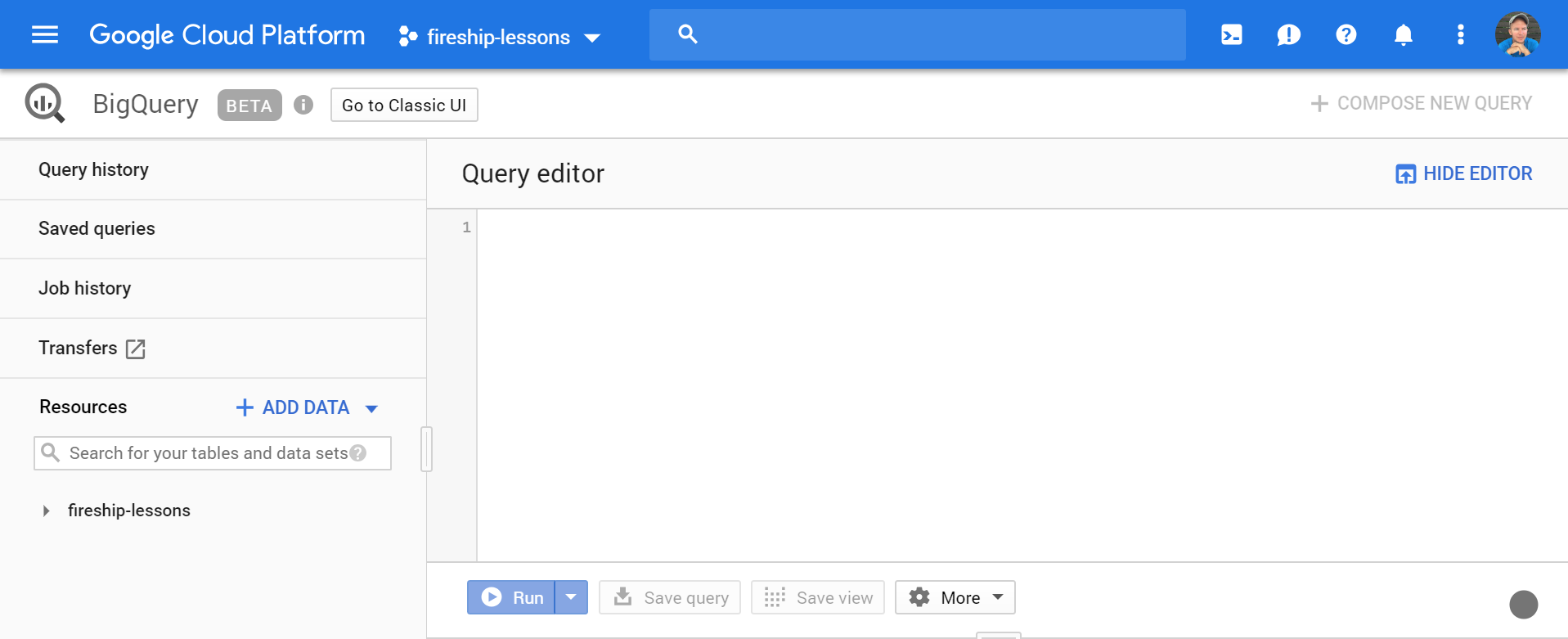
The big query web UI
Now that you have a dataset, you can start adding tables to it. Tables represent data that you query using SQL. You can define your own schema manually, but BigQuery can autodetect the schema of CSV files based on the header row and a random sample of rows. Click Create Table and reference the data in the storage bucket with the following options.
Follow these configuration options closely. Set the schema to auto-detect and the ‘Header rows to skip’ to 1 under the advanced tab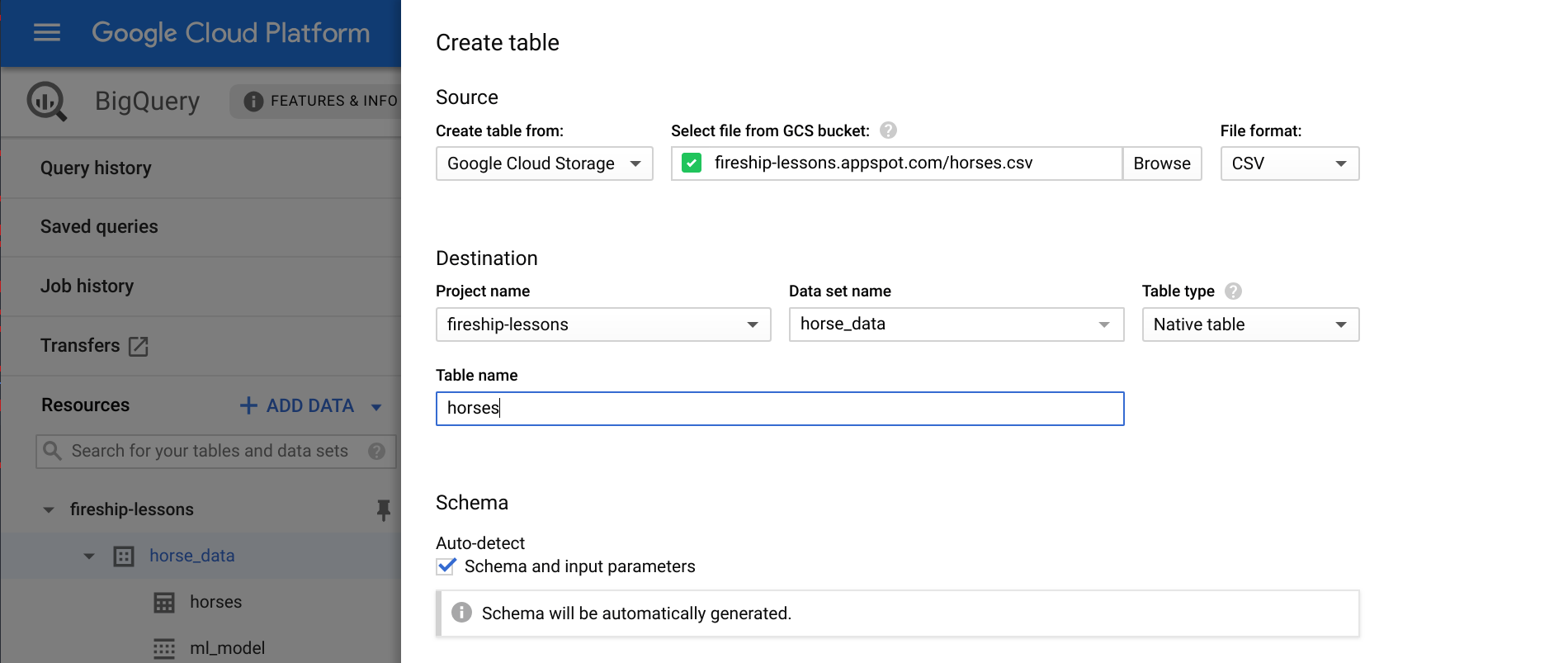
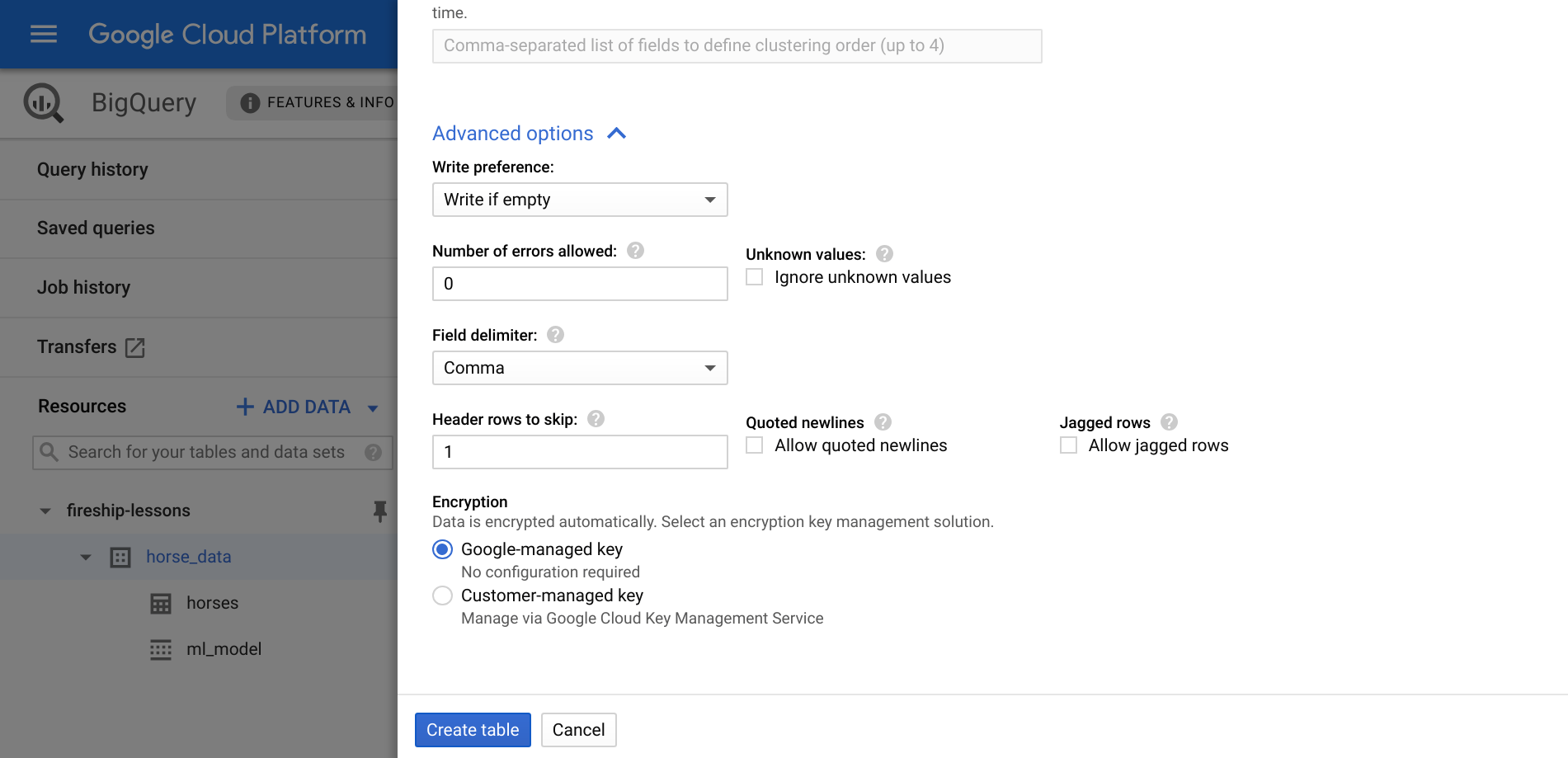
Make your First Query
The end result should be a table that looks just like the original spreadsheet. Enter a Standard SQL Query in the console to try it out. In this dataset, the position value represents a horse’s finishing position in a race, which is what we want to predict.
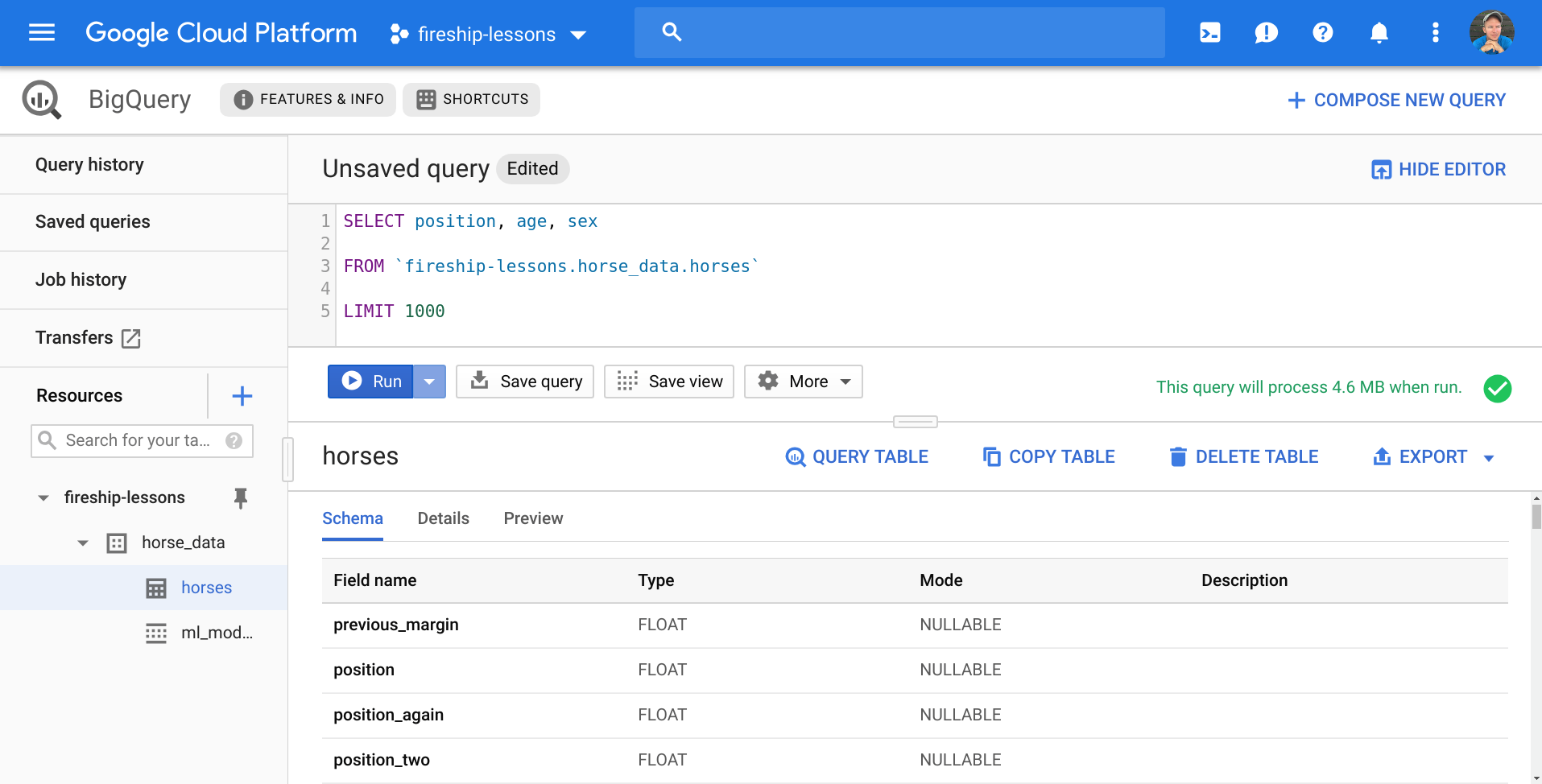
SELECT age, position, sex
FROM `fireship-lessons.horse_data.horses`
WHERE age > 2
LIMIT 1000
If the data looks malformatted at this point, you may need to open horses.csv in MS Excel and manually convert the number columns to numbers. BigQuery will error out if mismatched datatypes are present in the data.
Optional: Analyze in Data Studio
Make a query, then click Export -> Explore in Data Studio. A solid ML algorithm typically starts off with a thorough exploratory analysis. DataStudio will help you visualize the dataset and create custom charts.
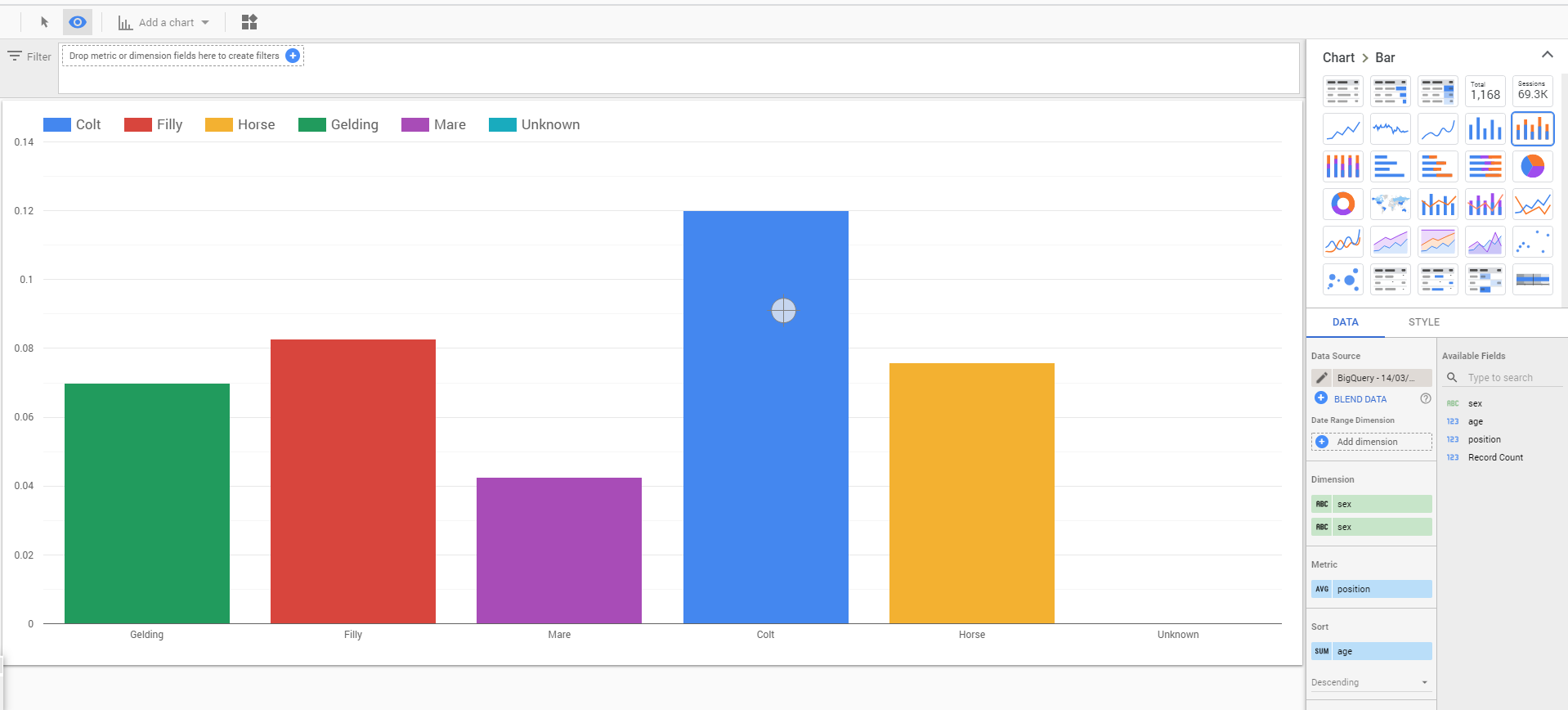
Create a Predictive ML Model
Now we’re ready for the fun part - converting our horse racing data into a predictive ML model. We will use another GCP service called DataLab, which connects a cloud VM to a Python notebook, along with a connection to your BigQuery dataset. In other words, it puts unlimited compute resources at your fingertips for training ML models on your data.
The DataLab instance will accrue costs. Make sure to delete the VM from the compute tab and any other resources after you are finished with this tutorial.
Open a Cloud Shell
Click on the Activate Cloud Shell button in the top right next your profile image. This opens a shell session that we can use to launch a DataLab instance.
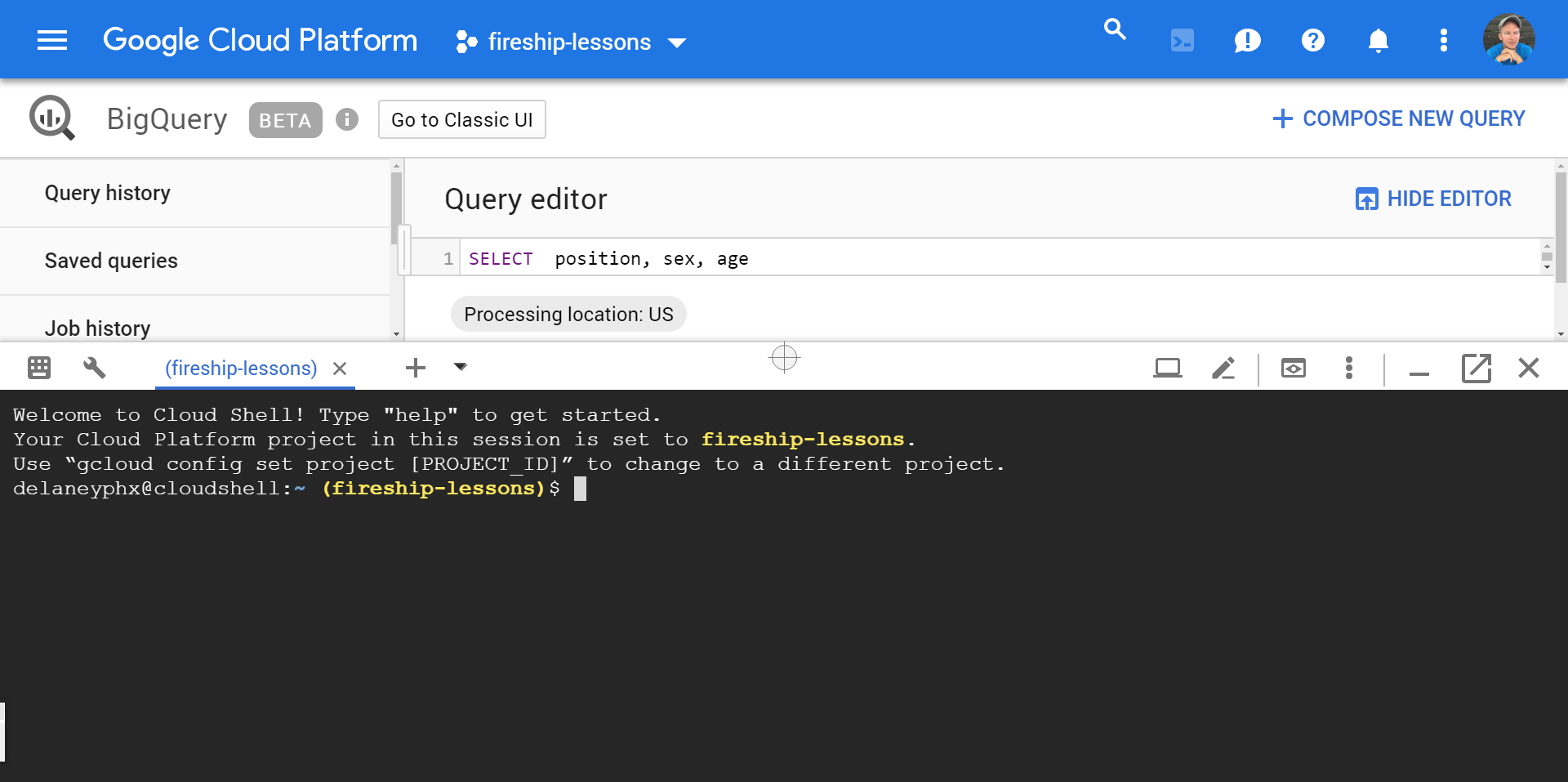
Enter the datalab create horsemagic command and follow the steps it gives you, which will result in an SSH tunnel on port 8081.
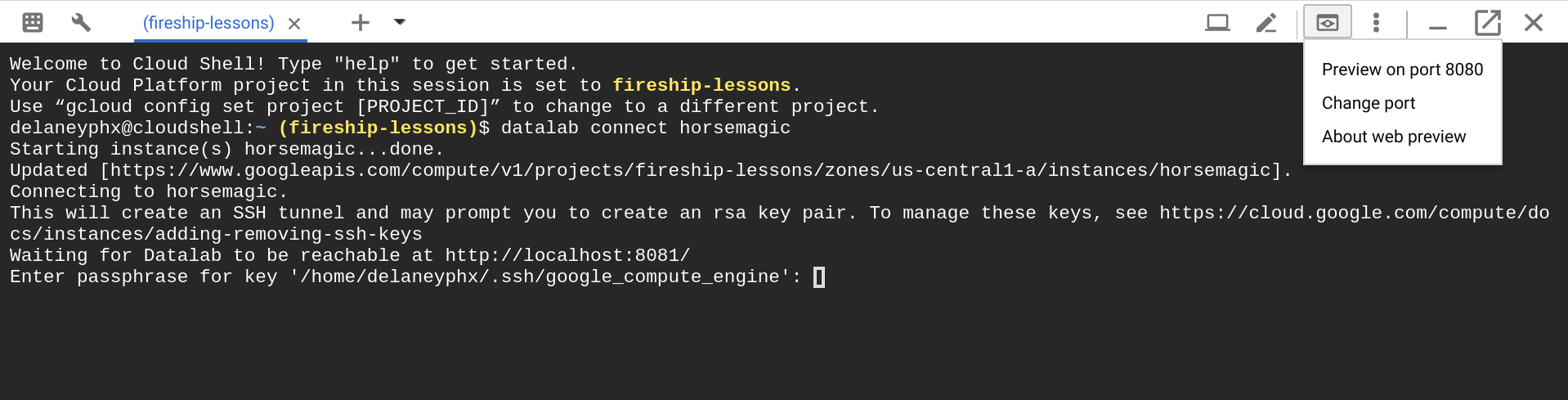
Open the web preview, but make sure to change the port to 8081
Access BigQuery from DataLab
Your BigQuery data is automatically available in the DataLab notebook. Create a new notebook, then get familiar with the available commands by running %% bq -h.
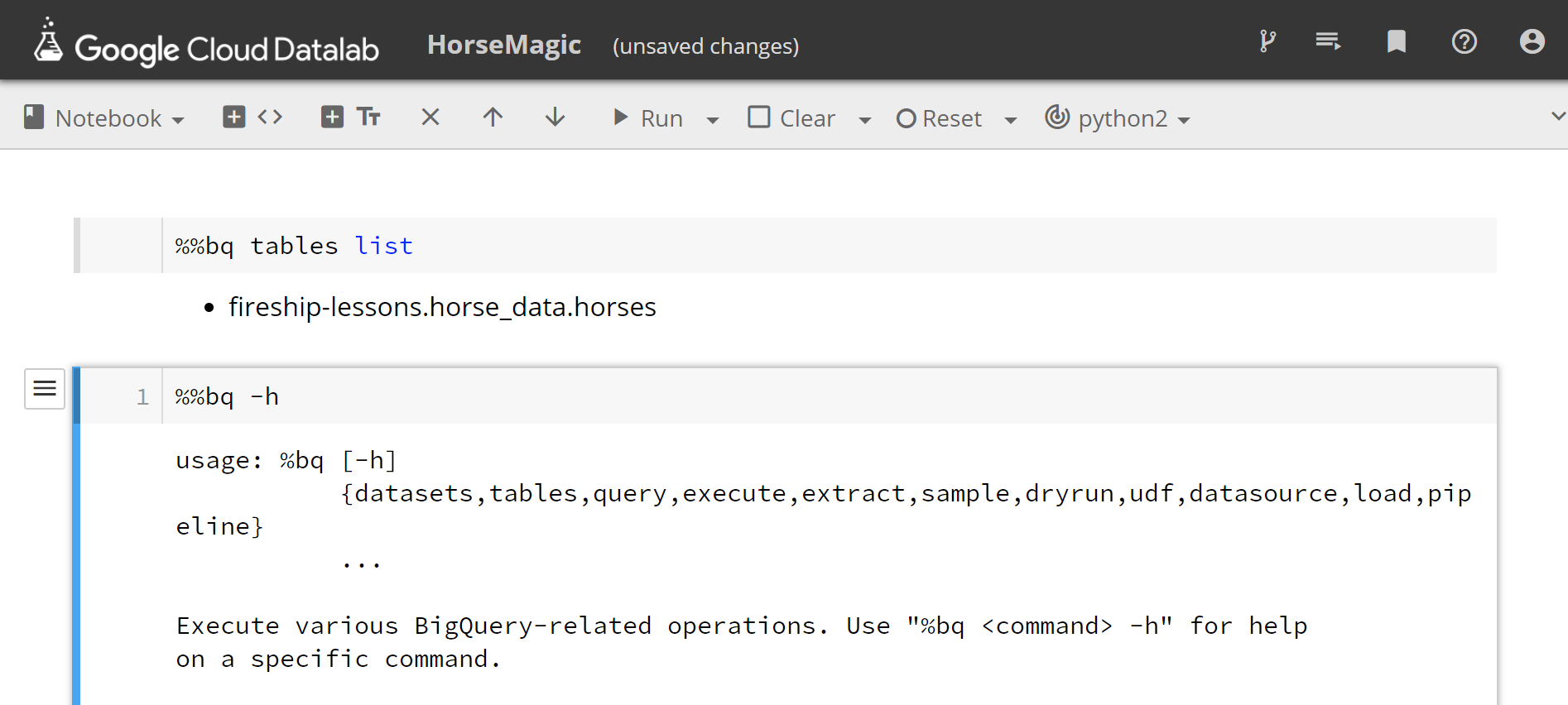
Run ‘%%bq tables list’ and you should see the table we created in BigQuery
Create a Model
Create a new cell in the notebook and run the code below, but make sure to use your own table names. Our goal is to predict the position label. This is a classification problem, so we use logistic_reg as the model type, then select the columns we think will result in the best predictions - feel free to change these and experiment. Reference the CREATE MODEL statement docs for additional BigQueryML options.
%%bq query
CREATE OR REPLACE MODEL `fireship-lessons.horse_data.ml_model`
OPTIONS
(model_type='logistic_reg',
input_label_cols=['position']) AS
SELECT
age,
sex,
overall_wins, overall_places, handicap_weight, penalty,
favourite_odds_win, number, runner_id, bf_odds, barrier, market_id,
position
FROM
`fireship-lessons.horse_data.horses`
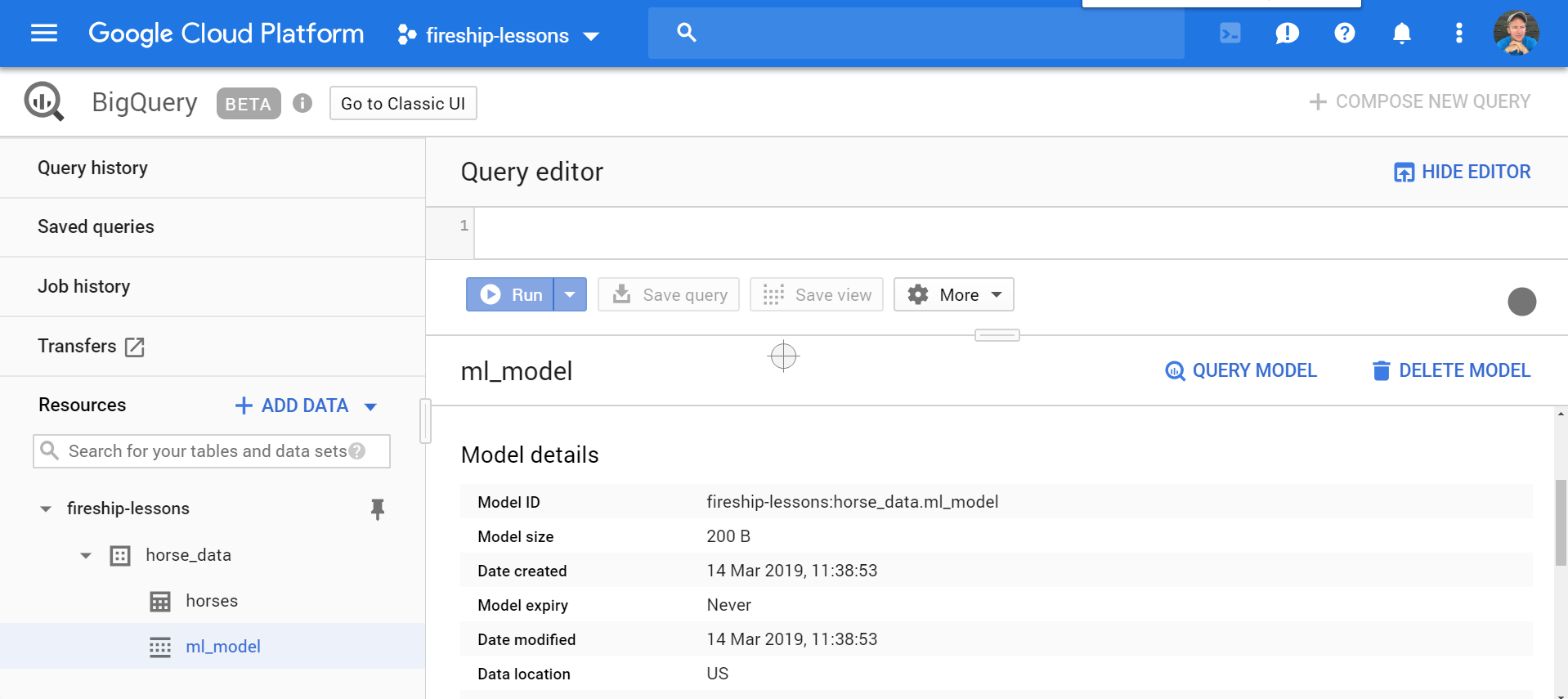
This will take a few minutes, then the ML model should appear in the BigQuery dataset
Evaluate Performance and Predict
For this particular ML problem, we are interested in the log_loss metric - a smaller value is better.
%%bq query
SELECT
*
FROM
ML.EVALUATE(MODEL `fireship-lessons.horse_data.ml_model`,
(
SELECT
age,
sex,
overall_wins, overall_places, handicap_weight, penalty,
favourite_odds_win, number, runner_id, bf_odds, barrier, market_id,
position
FROM
`fireship-lessons.horse_data.horses`
)
)
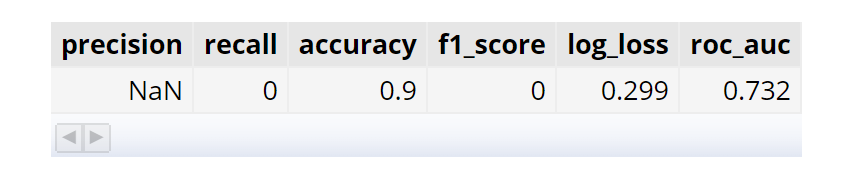
At this point, we’re happy with our model and it should pick the right winner for every horse race, therefore making us extremely wealthy 🤑. To make predictions, we can add new tables to our database with the same schema, then use the ML.PREDICT statement. In this example, I am just taking 10 random samples from the existing data.
%%bq query
SELECT
sex, runner_id, position
FROM
ML.PREDICT(MODEL `fireship-lessons.horse_data.ml_model`,
(
SELECT
age,
sex,
overall_wins, overall_places, handicap_weight, penalty,
favourite_odds_win, number, runner_id, bf_odds, barrier, market_id,
position
FROM
`fireship-lessons.horse_data.horses`
ORDER BY RAND()
LIMIT 10
)
)
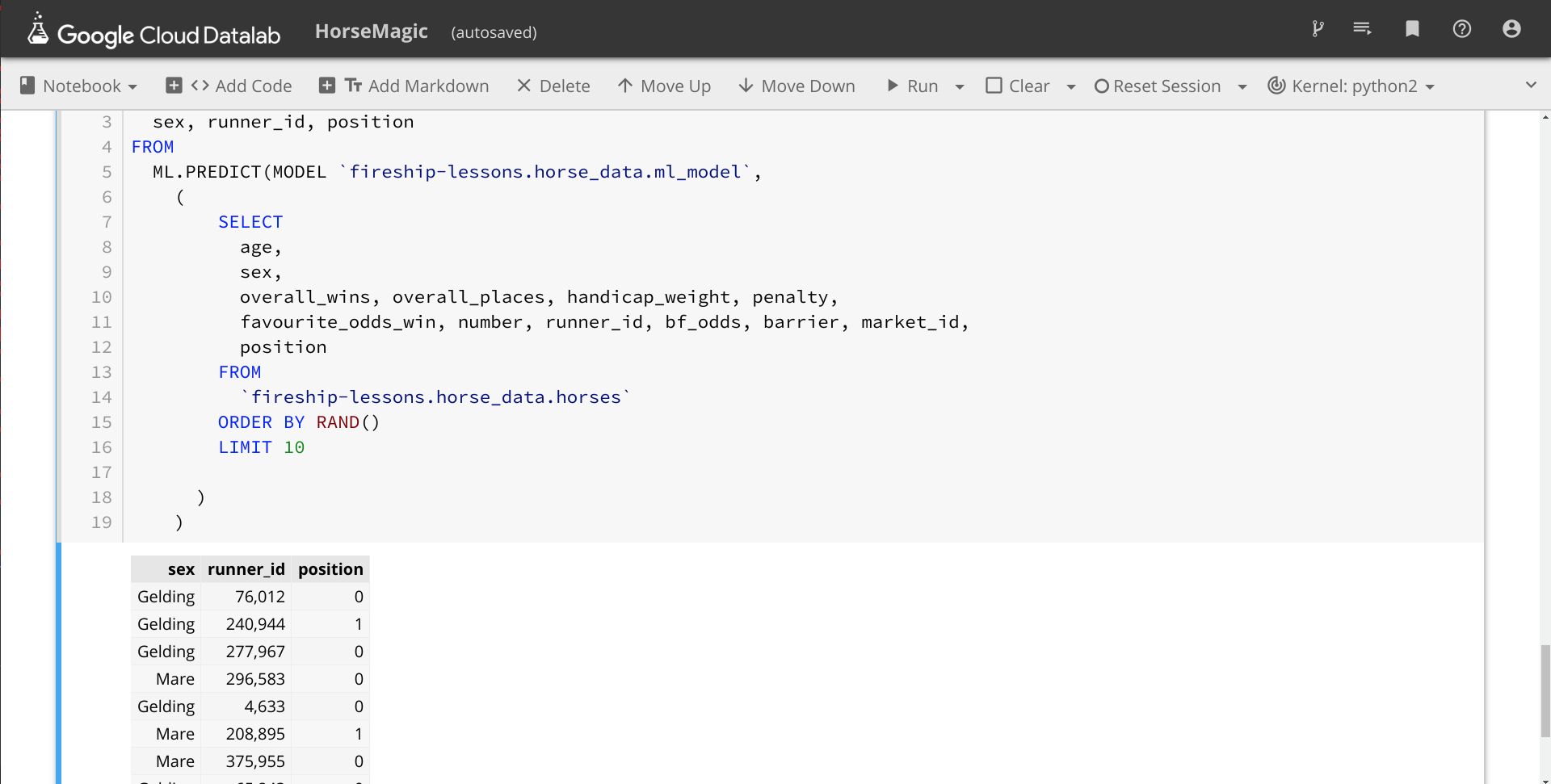
The final model predictions that we can take to the racetrack