
Modern Web Scraping Guide
In a perfect world, every website provides free access to data with an easy-to-use API… but the world is far from perfect. However, it is possible to use web scraping techniques to manually extract data from websites by brute force. The following lesson examines two different types of web scrapers and implements them with NodeJS and Firebase Cloud Functions.
Initial Setup
Let’s start by initializing Firebase Cloud Functions with JavaScript.
firebase init functions
cd functions
npm run serve
Strategy A - Basic HTTP Request
The first strategy makes an HTTP request to a URL and expects an HTML document string as the response. Retrieving the HTML is easy, but there are no browser APIs in NodeJS, so we need a tool like cheerio to process DOM elements and find the necessary metatags.
The advantage 👍 of this approach is that it is fast and simple, but the disadvantage 👎 is that it will not execute JavaScript and/or wait for dynamically rendered content on the client.
Link Preview Function
💡 It is not possible to generate link previews entirely from the frontend due to Cross-Site Scripting vulnerabilities.
An excellent use-case for this strategy is a link preview service that shows the name, description, and image of a 3rd party website when a URL posted into an app. For example, when you post a link into an app like Twitter, Facebook, or Slack, it renders out a nice looking preview.
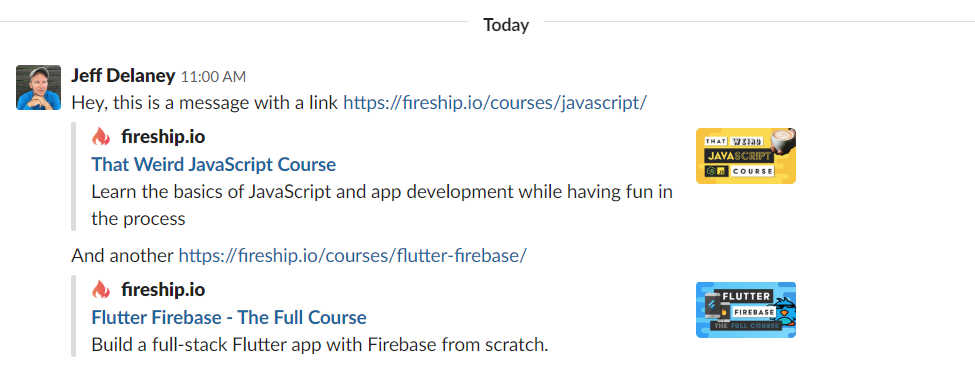
Link previews are made possible by scraping the meta tags from <head> of an HTML page. The code requests a URL, then looks for Twitter and OpenGraph metatags in the response body. Several supporting libraries are used to make the code more reliable and simple.
- cheerio is a NodeJS implementation of jQuery.
- node-fetch is a NodeJS implementation of the browser Fetch API.
- get-urls is a utility for extracting URLs from text.
cd functions
npm i cheerio node-fetch get-urls cors
Let’s start by building a
const cheerio = require('cheerio');
const getUrls = require('get-urls');
const fetch = require('node-fetch');
const scrapeMetatags = (text) => {
const urls = Array.from( getUrls(text) );
const requests = urls.map(async url => {
const res = await fetch(url);
const html = await res.text();
const $ = cheerio.load(html);
const getMetatag = (name) =>
$(`meta[name=${name}]`).attr('content') ||
$(`meta[name="og:${name}"]`).attr('content') ||
$(`meta[name="twitter:${name}"]`).attr('content');
return {
url,
title: $('title').first().text(),
favicon: $('link[rel="shortcut icon"]').attr('href'),
// description: $('meta[name=description]').attr('content'),
description: getMetatag('description'),
image: getMetatag('image'),
author: getMetatag('author'),
}
});
return Promise.all(requests);
}
HTTP Function
You can use the scraper in an HTTP Cloud Function.
const functions = require('firebase-functions');
const cors = require('cors')({ origin: true});
exports.scraper = functions.https.onRequest( async (request, response) => {
cors(request, response, async () => {
const body = JSON.parse(request.body);
const data = await scrapeMetatags(body.text);
response.send(data)
});
});
At this point, you should receive a response by opening http://localhost:5000/YOUR-PROJECT/REGION/scraper
Strategy B - Puppeteer for Full Browser Rendering
What if you want to scrape a single page JavaScript app, like Angular or React? Or maybe you want to click buttons and/or log into an account before scraping? These tasks require a fully emulated browser environment that can parse JS and handle events.
Puppeteer is a tool built on top of headless chrome, which allows you to run the Chrome browser on the server. In other words, you can fully interact with a website before extracting the data you need.
Instagram Scraper
Instagram on the web uses React, which means we won’t see any dynamic content util the page is fully loaded. Puppeteer is available in the Cloud Functions runtime, allowing you to spin up a chrome browser on your server. It will render JavaScript and handle events just like the browser you’re using right now.
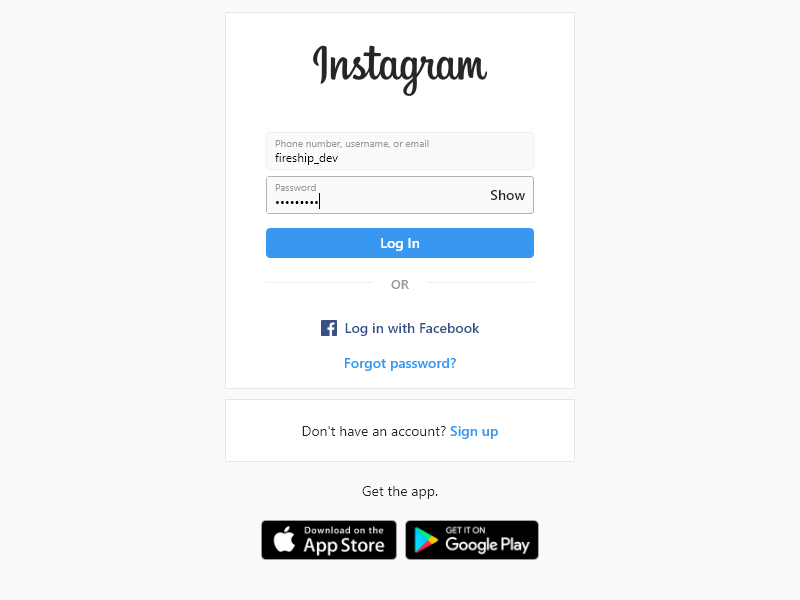
First, the function logs into a real instagram account. The page.type method will find the corresponding DOM element and type characters into it. Once logged in, we navigate to a specific username and wait for the img tags to render on the screen, then scrape the src attribute from them.
const puppeteer = require('puppeteer');
const scrapeImages = async (username) => {
const browser = await puppeteer.launch( { headless: true });
const page = await browser.newPage();
await page.goto('https://www.instagram.com/accounts/login/');
// Login form
await page.screenshot({path: '1.png'});
await page.type('[name=username]', 'fireship_dev');
await page.type('[name=password]', 'some-pa$$word');
await page.screenshot({path: '2.png'});
await page.click('[type=submit]');
// Social Page
await page.waitFor(5000);
await page.goto(`https://www.instagram.com/${username}`);
await page.waitForSelector('img ', {
visible: true,
});
await page.screenshot({path: '3.png'});
// Execute code in the DOM
const data = await page.evaluate( () => {
const images = document.querySelectorAll('img');
const urls = Array.from(images).map(v => v.src);
return urls
});
await browser.close();
console.log(data);
return data;
}